Hi all!
First of all, many thanks for these comments. We went back to reviewing the code and we found one issue with the data processing. As with past issues, there is a fix already available in the firmware and it will be included in the next main release, but if you want to test it, use the instructions here to flash it and use the *.uf2 file that you can find here.
Below comes an in depth explanation of the issue, so get ready!
First let’s talk about how we process the noise samples. The whole in depth explanation is detailed in this series of posts (I, II, III), but we will make a summary here.
-
Noise is sampled by a MEMS microphone by Invensense (TDK) ICS43432, at 44.1kHz. We take 512 samples, as this gives us a reasonably good noise spectrum, from very low frequencies (<100Hz) up to 22.05kHz. This basically covers human hearing in general (except for super humans and that kind of thing).
-
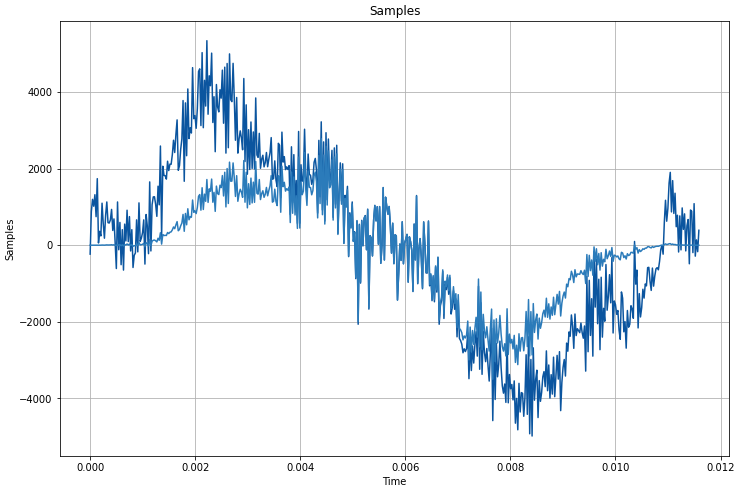
The samples are then windowed using a hann window. This table is here and is applied to the samples here. Some raw and windowed samples are shown below for some tests I conducted at home. Mainly, the window is used to avoid introducing frequencies into the FFT (below) that are a byproduct of the discrete sampling process, or in other words, to smooth out the edges of our samples and avoid having peaks in the spectrum that do not exist.
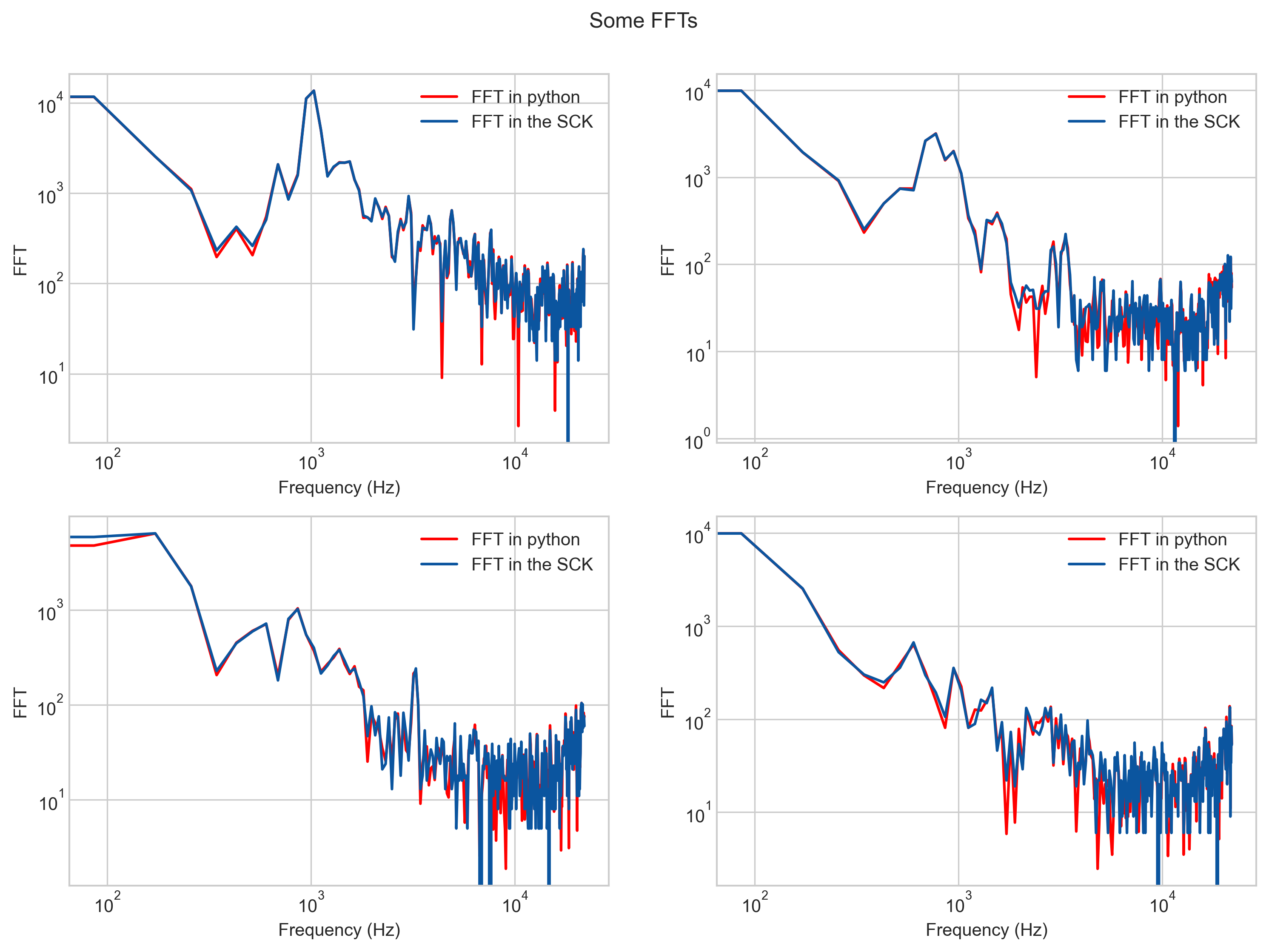
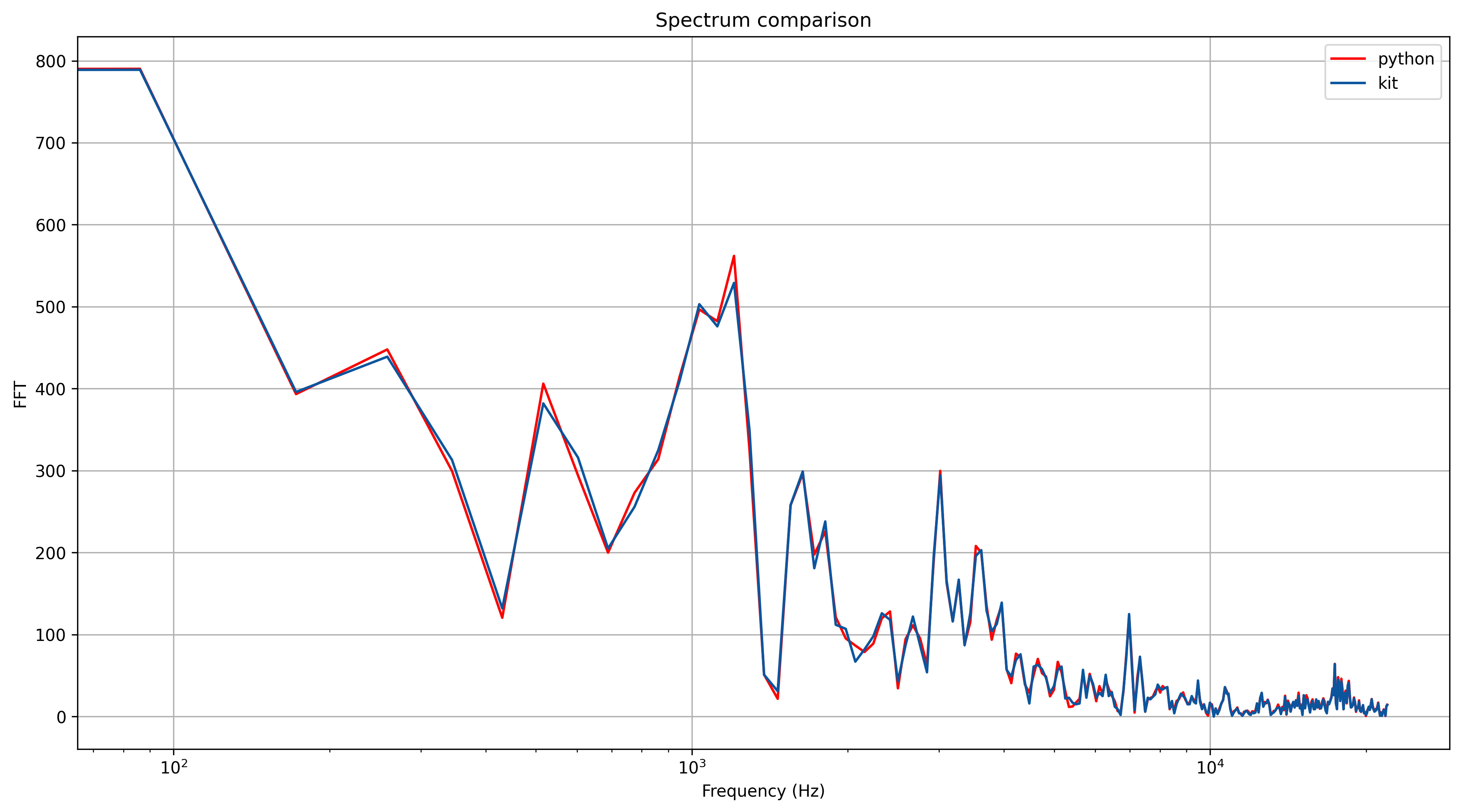
- With the windowed sample, we calculate the FFT algorithm. The implementation is a custom version based on Adafruit ZeroFFT because arm’s DSP core for making this operation is way too large for the SAMD21 chip and literally leaves no room for other things in the firmware. Therefore, we had to apply the algorithm ourselves by using these two lines and these two tables. The resulting FFT, calculated using this process, and compared with an FFT done in python is shown below. Luckily, the match almost perfectly (phew!)
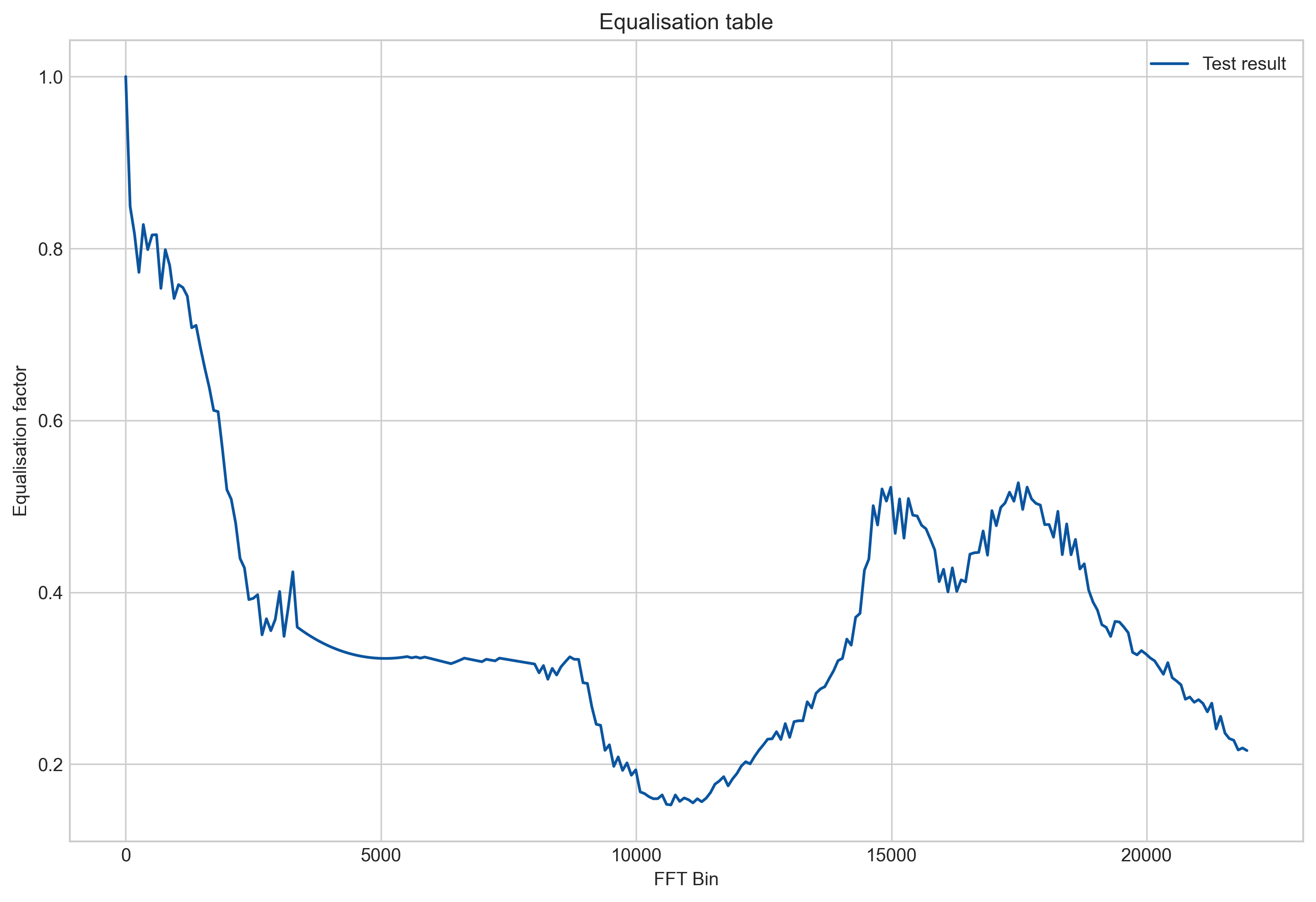
- Once we have the FFT spectrum, we perform two processes: equalisation and weighting. The equalisation process basically tries to correct the microphone response and make it linear. This is because the microphone responds by amplifying some frequencies more than other and we compensate this. To do so, we performed tests in an anechoic chamber and we extracted this equalisation table. This table matches roughly the response of the microphone, but also some other resonances from the urban board.
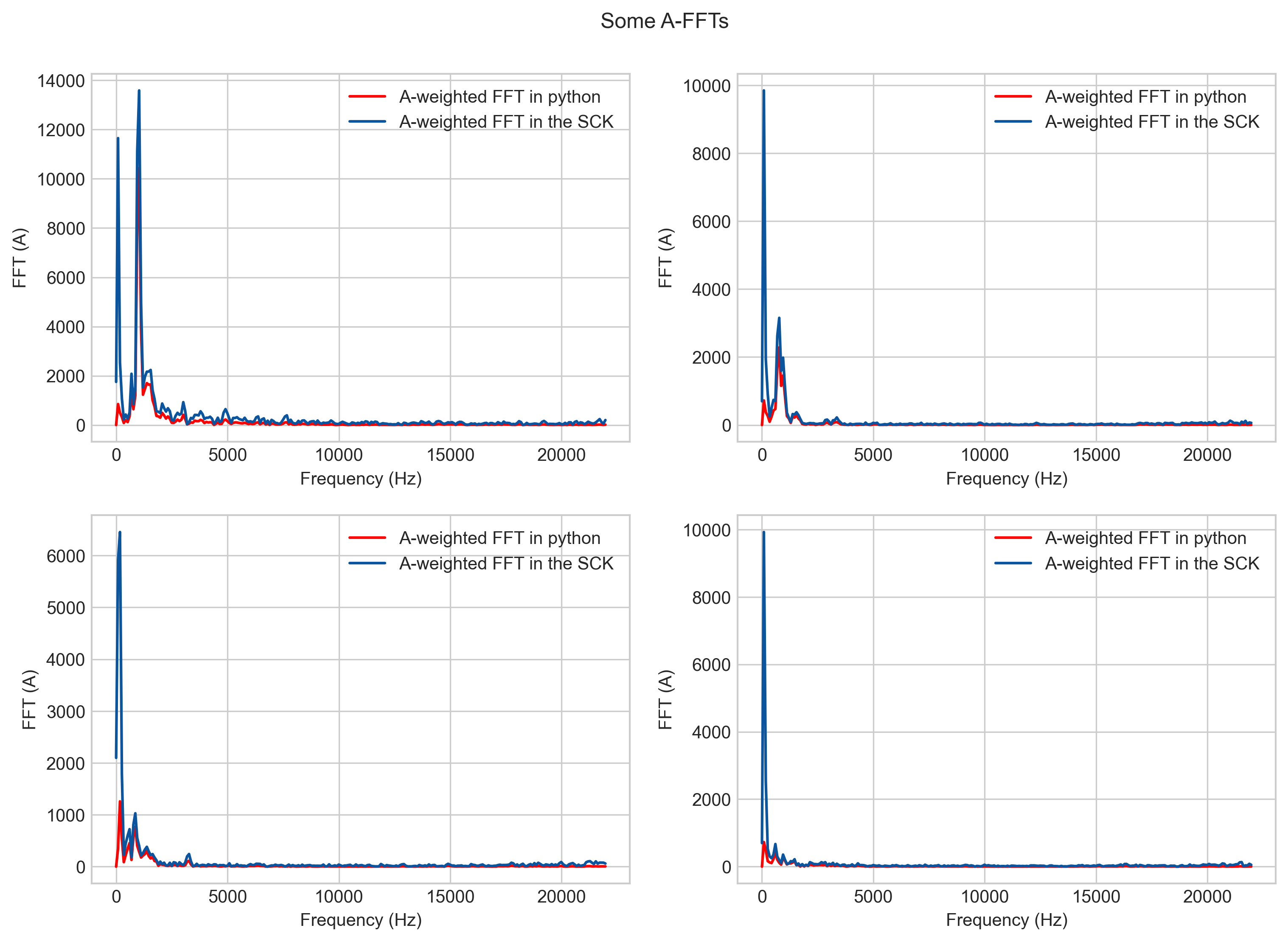
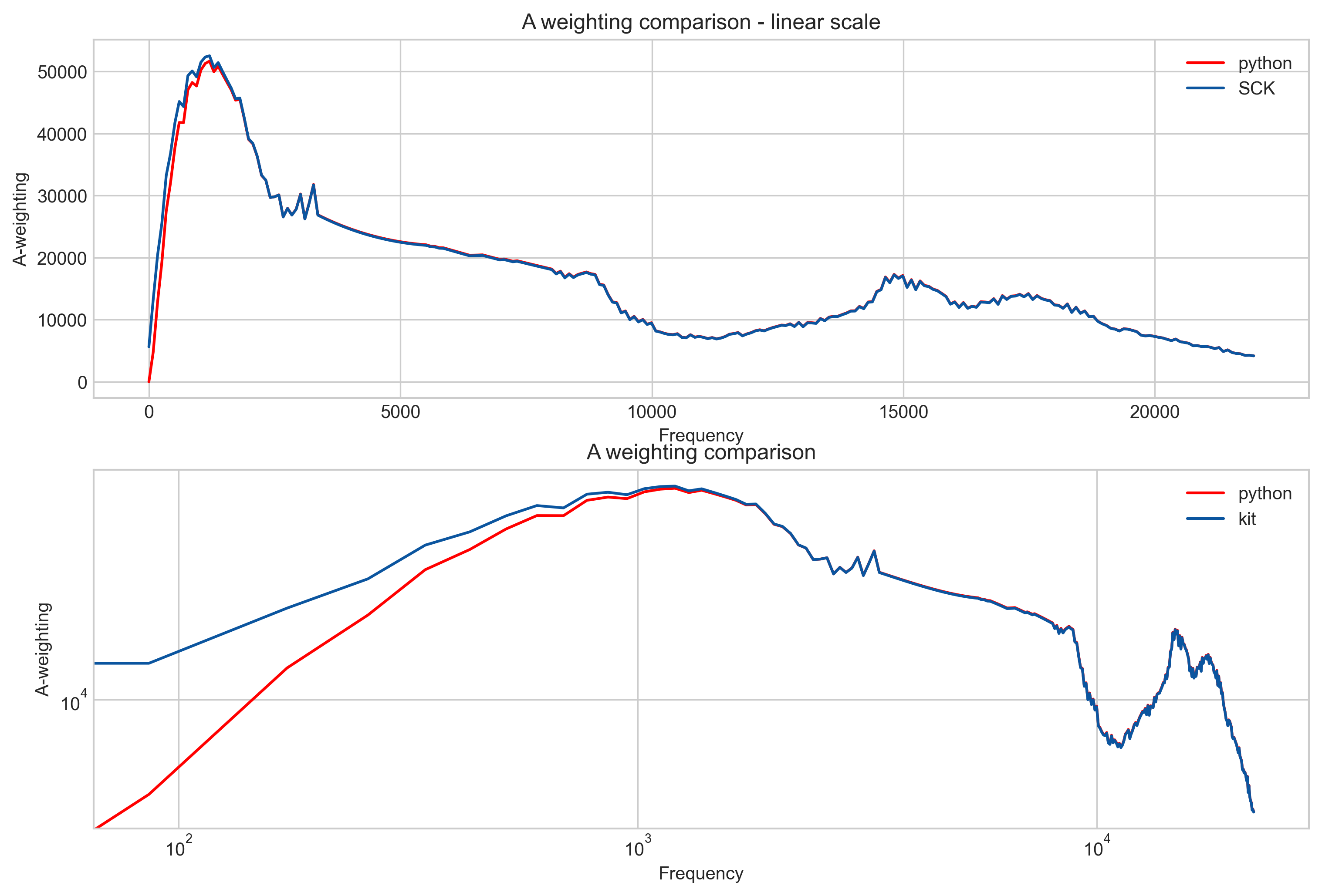
With this, we go on to the weighting, we apply A or C weighting to the samples:
Since these two processes can be combined, we put them in one single table for each weighting (A and C) and made them easier to handle by the chip by making them in the range of 0-65535.
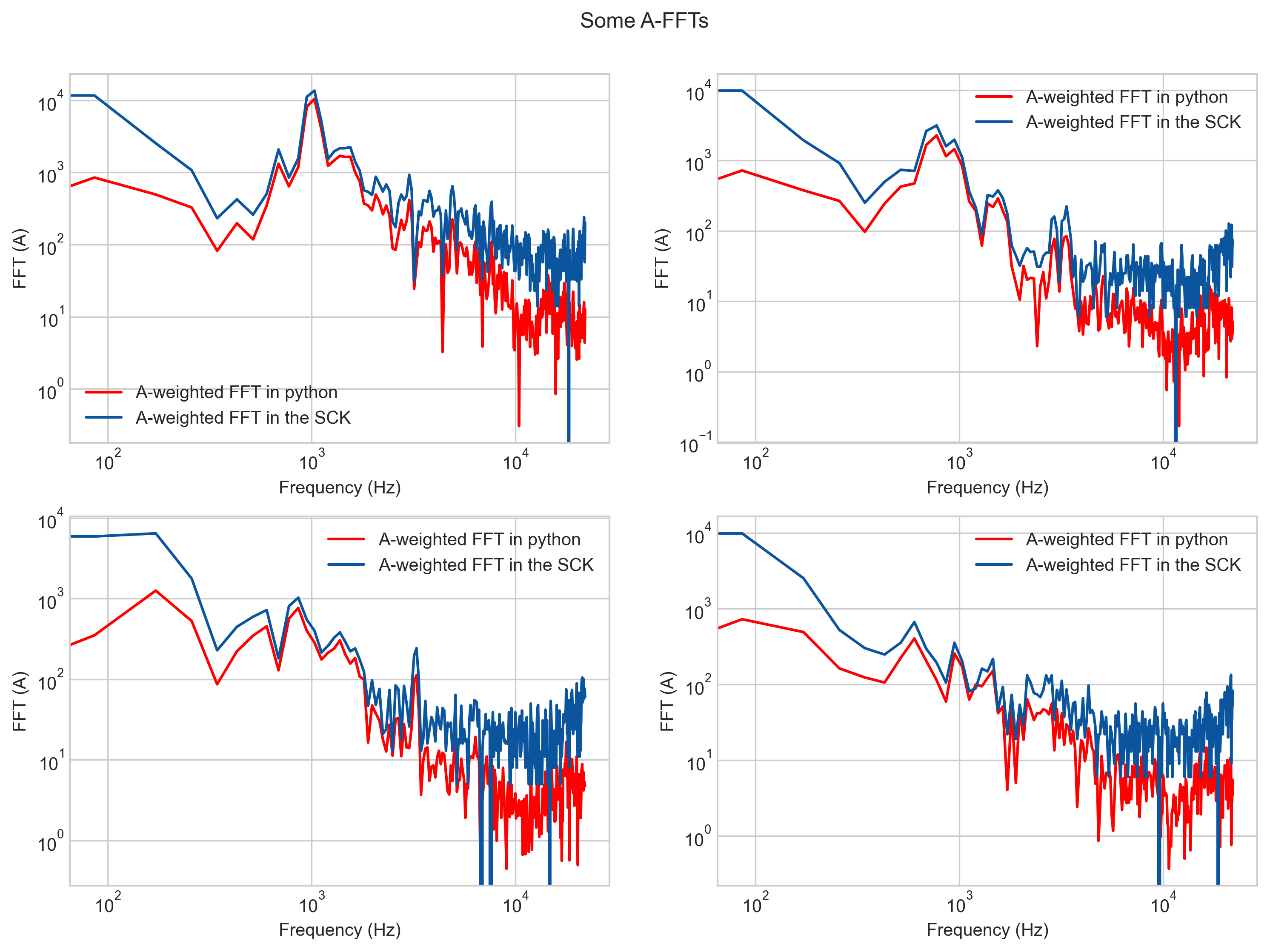
Looking closely enough, or in the log plot, you can see how: 1. some numerical errors start happening (not as bad), but more importantly, 2. the lowest frequency area doesn’t match at all! If we compare the RMS values now, we start to see a difference, specially for those spectrums that do not contain much information out of the f<500Hz.
And here is the mistake  … The combination of the equalisation tables and the weighting was not right in the firmware, specially for A weighting:
… The combination of the equalisation tables and the weighting was not right in the firmware, specially for A weighting:
This makes, that in quiet environments, there is an error by this “amplification” or better, lack of weighting. If we compare the RMS errors (in dB scale) in all four samples, we see how the lower we go in absolute spls, the worse this error becomes relative to the overall spectrum:
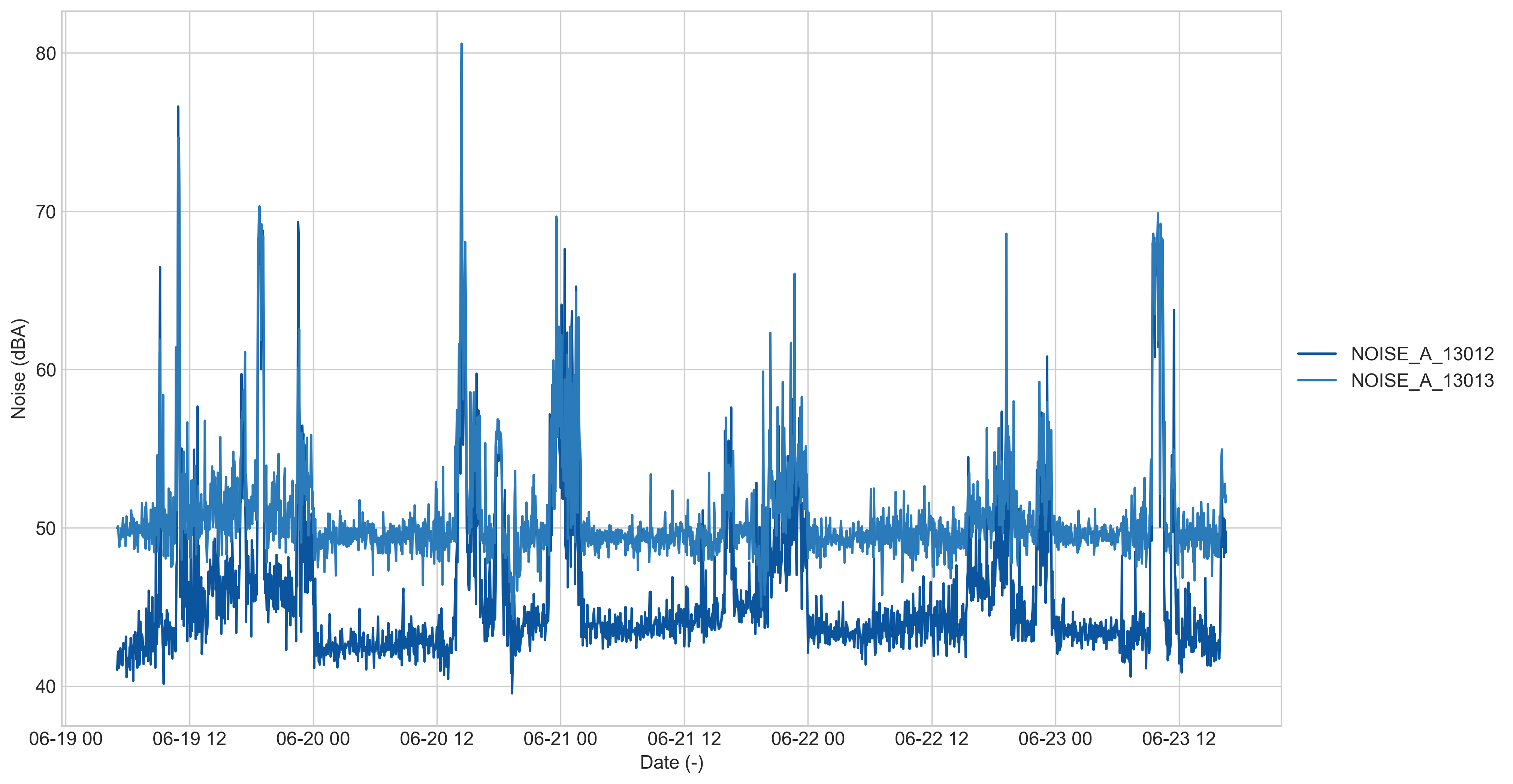
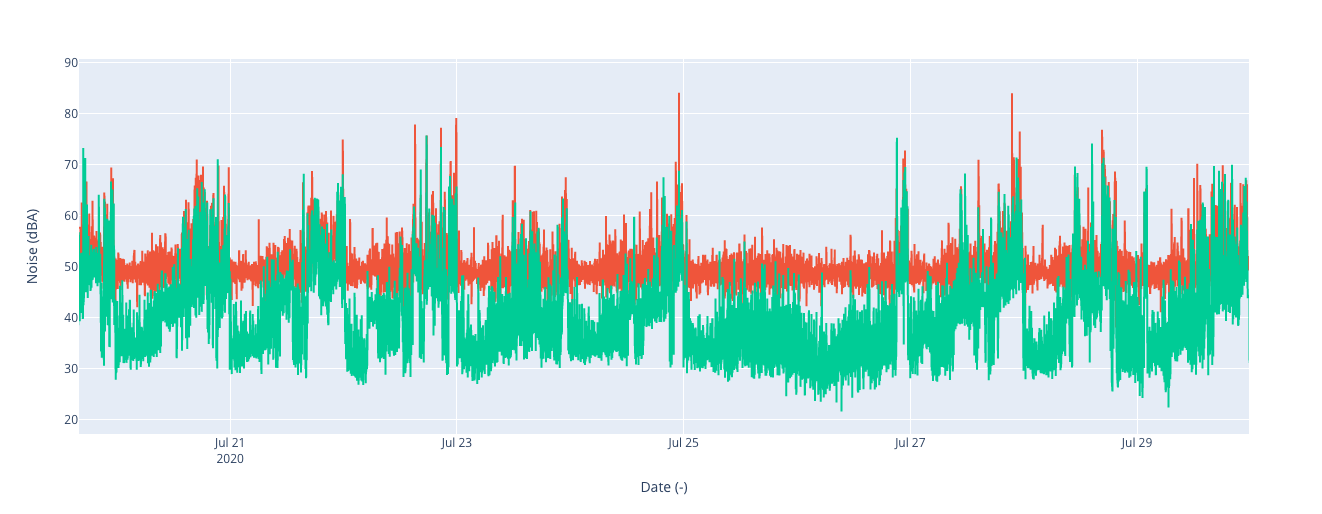
If now we measure with to SCKs, one with the fix and one without in an office environment (aka my room these days) and various noises around for testing, we can see how this bottom threshold is lowered:
Bug version: http://smartcitizen.me/kits/13013
New version: http://smartcitizen.me/kits/13012
Some questions might arise:
- Can measurements already recorded be fixed? No
- Can this be fixed? Yes. See the firmware comment above.
- Does this affect all the measurements? No, only those with very low frequencies and below 50-52dB approx.
- Is this it? In principle yes, but I invite you to test it and give us feedback, also to check the source code in the firmware and the python analysis below to see if we made any mistake in the process.
Note: all this processing is also available in this python notebook in case you want to review the calculations yourselves.
Thank you very much for your understanding and again, for commenting here and making us come back to the numbers and check the values.